题目要求:
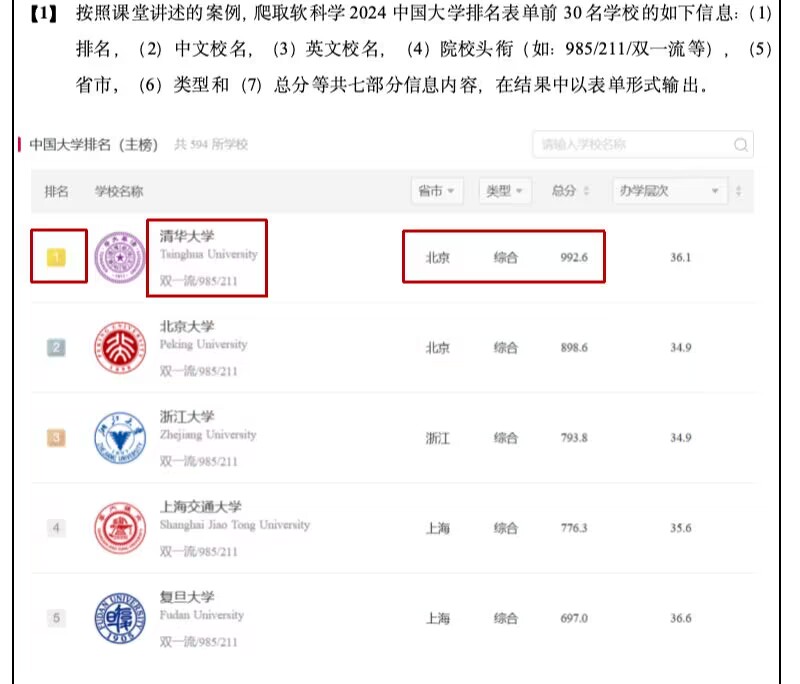
以下是一个不是很完美的解决方案:
import requests
from bs4 import BeautifulSoup
import bs4
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '连接失败'
def fillUniList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
tbody = soup.find('tbody')
if tbody:
for tr in tbody.find_all('tr')[:30]: # 仅获取前30名学校
td = tr.find_all('td')
# 在第二列中找到包含中文校名、英文校名和院校头衔的字符串
name_title_text = td[1].text.strip()
# 使用正则表达式来提取中文校名、英文校名和院校头衔
name_title_pattern = r'(.+)\s{2,}(.+)\s{2,}(.+)'
match = re.match(name_title_pattern, name_title_text)
if match:
chinese_name = match.group(1)
english_name = match.group(2)
university_title = match.group(3)
else:
chinese_name = ''
english_name = ''
university_title = ''
ulist.append([td[0].text.strip(), chinese_name, english_name, university_title, td[2].text.strip(), td[3].text.strip(), td[4].text.strip()])
def printUniList(ulist):
tpl = "{:^5}\t{:^18}\t{:^44}\t{:^30}\t{:^12}\t{:^12}\t{:^5}"
print(tpl.format('排名', '中文校名', '英文校名', '院校头衔', '省市', '类型', '总分', chr(12288)))
for u in ulist:
print(tpl.format(u[0], u[1], u[2], u[3], u[4], u[5], u[6], chr(12288)))
def main():
ulist = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2024'
html = getHTMLText(url)
fillUniList(ulist, html)
printUniList(ulist)
if __name__ == '__main__':
main()运行效果如下:
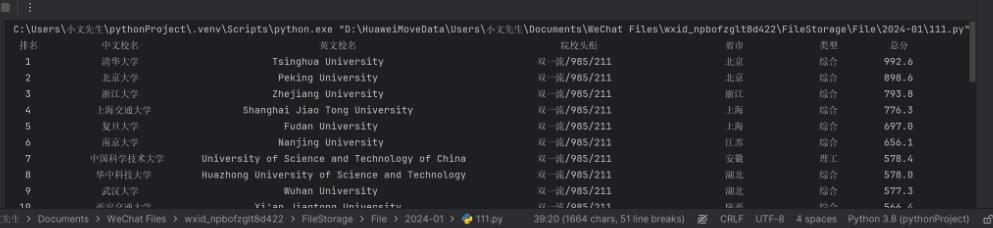
可以看到对齐效果不是很好,一个解决思路是使用chr(12288)填充中文空格,可以尝试解决
